skip to main |
skip to sidebar
 Harry Campbell asked
Harry Campbell asked A rather trivial question perhaps, but why is netsuke conventionally pronounced "netski"? Amittedly LPD allows a three-syllable variant, but I can't see why a vowel that is present in Japanese should be completely elided (even in careful speech) in English.
If you’re not sure what a netsuke (根付) is, there’s a helpful Wikipedia article here.
The LPD entry for netsuke reads ˈnet ski -skeɪ; ˈnets ʊk i, -eɪ — Jp [ne ˌtsɯ̥ ke]
My decision to prioritize ˈnet ski was based on what I have heard antiques experts say on television. I see that CEPD prioritizes the -skeɪ variant, but its authors and I agree that the most common pronunciation in English has only two syllables. So why? I told Harry The vowel is not "present" in the phonetic sense in Japanese, even though it may be there phonologically. High vowels in Jp are normally elided between voiceless consonants.
His reaction was So this would be a case of the English spelling being a transcription of the Japanese orthography/phonology while the pronunciation reflects a surprisingly sophisticated awareness of the pronunciation (though the elision isn't mentioned in LPD's transcription of the Japanese)? -- a situation which strikes me as unusual. After all we don't write "a certain je ne sais quoi" but make a point of saying "je n' sais quoi". (Not a great example perhaps but you see what I mean.)
I wonder if the snobbery surrounding antiques helps to enforce this counter-intuitive pronunciation as a shibboleth, as with aristocratic names like Cholmondeley and Althorp and so on? I just find it odd.
It’s not clear how we should best transcribe these Japanese vowels. Which is best, ne ˌtsɯ ke, ne ˌtsɯ̥ ke, or ne ts ke? There’s a certain amount of regional and gender variation, but as I understand it the first represents a theoretical pronunciation that you might get if you asked a Japanese speaker to say the word very slowly and carefully, indicating the identity of each mora in turn. The second is still slow and careful. The third is the ordinary pronunciation.
Where an i or an ɯ is devoiced/elided in this way it may still leave a trace in the form of a secondary articulation on the preceding consonant, making /ki/ [kʲ] and /ku/ [kɯ]. There’s a nice minimal pair illustrating this point, but I can’t remember what it is — no doubt someone will tell us.
This Wikipedia account describes the devoicing, but does not allow for complete elision.
But in the simple question これはなんですか kore wa nan desu ka ‘what’s this?’ the last two words are typically pronounced not desɯka, not desɯ̥ka, but (to my ear at least) just deska.
Anyhow, Harry, the antiques dealers have clearly based their English pronunciation on the Japanese spoken form, not on the written romaji.
_ _ _
More public holidays. Next posting: 3 May
 My colleague Martin Barry, formerly of the University of Manchester, has been in the news recently.
My colleague Martin Barry, formerly of the University of Manchester, has been in the news recently.
You can discount the first sentence of the report to which the link leads. If you read the whole piece you will see that the forensic case Martin helped with did not actually involve “deciphering the words of an urban rapper” but rather testing the authenticity of the time stamp on a recording. If the recording had indeed been made at the time claimed by the accused it would have furnished an alibi to the charge of attempted murder. But Martin showed that the recording was identical to another one with a different time stamp, concluding that the first time stamp was false and the purported alibi invalid.
Martin is the second of my British colleagues, to my knowledge, to have resigned a university post in phonetics in order to go freelance as a forensic voice expert. (The other is Peter French.)
I suspect that most university phoneticians have been approached at one time or another to testify in court cases of this kind. My former colleague John Baldwin used to do a great amount of this kind of work, and unlike most forensic phoneticians relied on his listening skills rather than on instrumental laboratory evidence. (He was the subject of a leading judicial decision that the non-instrumental evidence of a trained phonetician is admissible as ‘expert testimony’ in British courts.)
Personally, I do not generally accept invitations to act in such cases. The only one in which I did become involved, many years ago, actually involved syntax rather than phonetics. It concerned a Trinidadian defendant who was contesting part of a written police statement reporting his words when being interrogated about some crime. The statement was ten pages long, and he agreed that the first eight and a half pages were accurate. He said that the last page and a half, where the damaging admissions were located, was not: he had never said the words alleged.
At the request of his lawyers, I examined the written statement. Then I asked him to come and see me. Without explaining what I was looking for, I set a tape recorder going and fed him with questions for an hour, just to keep him talking — about anything and everything.
I had noticed that in the transcribed sentences that he had denied uttering there were three passive constructions with agent phrases (of the type he was seen by the woman, I was asked by my friend, the window was broken by the children). I knew that for West Indians with the level of education of the accused such constructions are unusual. And so it proved: in the hour’s material I recorded — despite my covert attempts to elicit passive sentences with by-phrases — he uttered not a single one. It was a reasonable inference that the police had invented the parts of the written statement containing the passive sentences. (These sentences might have meant much the same as what he had actually said, but they could not be accepted as a verbatim record, which is what they purported to be.)
When his lawyers reported my finding to the prosecution, the latter decided to drop the main charge and proceed only with a minor one, which the accused admitted. So I never had my day in court.
 Ordinary words of any language can be represented as strings of phonemes of that language (together with indications of phonemic stress, tone etc., depending on the language). But there are some “words” that are exceptions to this generalization.
Ordinary words of any language can be represented as strings of phonemes of that language (together with indications of phonemic stress, tone etc., depending on the language). But there are some “words” that are exceptions to this generalization.
Clicks in many languages are a case in point. The sound represented in English spelling as tut, tut tut, tsk or tsk tsk is articulatorily a single or repeated click (often categorized as ‘dental’, though in English it’s generally actually alveolar) and is used to show disapproval or annoyance. It stands outside the phonological system, since it is not a phoneme of English (no lexical words include it), and it stands outside the syntactic system, since it does not enter into sentence structure (it’s not a constituent of any larger syntactic unit). So we call it ‘paralinguistic’. Note, though, that its meaning and use are language-specific. What applies in English does not necessarily apply in other languages. In Greek or Hebrew the same click sound does not show annoyance, but stands for ‘no’ (a cause of possible misunderstanding and dismay for English tourists asking, for example, if a ticket or room is available).
Sometimes there is quite a lot of variability in the identity of the ‘same’ paralinguistic interjection. In LPD I agonized over how best to show the pronunciation of ugh, the sound we make when something is extremely unpleasant or disgusting. I finally put ʊx ʌɡ, jʌx, ɯə, uː — and various other non-speech exclamations typically involving a vowel in the range [ɯ, u, ʌ, ɜ] and sometimes a consonant such as [x, ɸ, h]
There are other spellings in use, too, such as yuk, eeurgh, eeeuw.
The Guardian cartoonist Steve Bell puts this into the mouth of his French artist character as èrgue, which implies the pronunciation ɛʁɡ(ə). (I believe the real French equivalent is pouah pwɑ, which must lead to interesting punning possibilities when discussing weight poids or peas pois.)  To decipher the cartoon (click to enlarge) you have to know French spelling conventions and be familiar with the mangling English vowels stereotypically undergo in the mouths of the French — and you have to put the result into nonrhotic English, e.g. “murney” = money.
To decipher the cartoon (click to enlarge) you have to know French spelling conventions and be familiar with the mangling English vowels stereotypically undergo in the mouths of the French — and you have to put the result into nonrhotic English, e.g. “murney” = money.
What started this train of thought was a FB status by my nephew.  I haven’t got meh in LPD. It can’t have been around for more than about ten years, if that (can it?). I obviously ought to put it in the next edition. It means something like ‘I’m not impressed’ or ‘I don’t feel very enthusiastic’. It’s pronounced me (like met but without the final t), which IS a string of English phonemes but violates the phonotactic constraint that disallows words ending in the DRESS vowel.
I haven’t got meh in LPD. It can’t have been around for more than about ten years, if that (can it?). I obviously ought to put it in the next edition. It means something like ‘I’m not impressed’ or ‘I don’t feel very enthusiastic’. It’s pronounced me (like met but without the final t), which IS a string of English phonemes but violates the phonotactic constraint that disallows words ending in the DRESS vowel.
Was it the Simpsons who invented this addition to our paralinguistic repertoire? Or at least who popularized it?
Steve Doerr draws my attention to the fact that for yesterday’s OED Word of the Day, which was monstrous, the first AmE pronunciation given is ˈmɑnztrəs. Here’s the top of the OED entry for this word.  He comments
He comments The pronunciation with /-z-/ is unknown to both LPD and CEPD.
 …and, I might add, to all other reference books I have to hand — with one exception. That exception is the Oxford Dictionary of Pronunciation (alongside), which comes from the same stable as the OED.
…and, I might add, to all other reference books I have to hand — with one exception. That exception is the Oxford Dictionary of Pronunciation (alongside), which comes from the same stable as the OED.
My gut feeling is that it’s pretty bizarre to claim that Americans (or anyone else) typically pronounce nzt rather than nst in monstrous, particularly since no z pronunciation is suggested for the base form monster. It looks to me more like an individual idiosyncratic mislearning of the pronunciation of a particular word.
Looking further into ODP, however, I find that that doesn’t seem to be the case. In that dictionary AmE z variants, always prioritized, are given not only for monstrous but also inter alia for inscription, inscrutable, inscribe, inspire, instant, instinct, institute, instruct, instruction, instrument and monstrosity. As I say, there is no such variant suggested for monster, nor for demonstrative or demonstrate, nor (for example) for constable, constellation, constipation, constitution, constant, gangster, hamster, inspiration, instructive, instructor, seamstress.
As you can see, I have examined an assortment of words in which the usual pronunciation has nasal plus s plus plosive. But as far as I can see there doesn’t seem to be any consistency in this matter. Do people really treat monster differently from monstrous, inspire differently from inspiration, instruct differently from instructor?
I wonder if Bill Kretzschmar, the author who presumably contributed these pronunciation entries, would care to comment.
_ _ _
Happy Easter, everyone. Next posting: 26 April.
 The Guardian newspaper used to be a byword for typographical errors of one kind and another, which is where its nickname the Grauniad comes from.
The Guardian newspaper used to be a byword for typographical errors of one kind and another, which is where its nickname the Grauniad comes from.
Those days are gone. But occasional errors remain, here as elsewhere. (And as someone who commits the odd typing error from time to time myself, I’m in no position to throw stones.)
It is when a spelling mistake is repeated several times in the same article that one begins to feel critical. Yesterday’s paper had a health article by Patrick Kingsley devoted to macular disease, the eye condition that can lead to blindness.
Although the disease is correctly referred to as macular, the part of the eye affected is the macula. We nonrhotic speakers pronounce the two terms identically, but the noun is correctly spelt without r, the adjective with.
Patrick Kingsley got it wrong, spelling both terms macular. In the version now available on the website the spelling has been corrected and there is an embarrassed apology.
In the version now available on the website the spelling has been corrected and there is an embarrassed apology.
The fact that even highly literate university graduates such as Guardian journalists still have difficulties with English spelling supports the view that it ought to be reformed. However any reform intended to apply to English as a whole would have to retain the letter r in those positions where rhotic speakers (who are the majority) retain it. So nonrhotic speakers are still going to have to learn and apply spelling differences that from our point of view are unpredictable, arbitrary: perhaps cawt (caught) vs. cort (court), even though they are homophones for us.
Even if we reform our spelling it’s going to have to be marimba but timber, Virginia but linear, necrophilia but familiar, and umbrella but cellar, not to mention lava and larva. Tough.
So it is with macula and macular, and likewise for the exactly parallel uvula – uvular, peninsula – peninsular. Classicists will recognize Latin first-declension nouns in -ă and their corresponding adjectives in -ār(is).
Still on spelling: today’s paper has a piece mentioning the Welsh historical figure Owen Glendower, or Owain Glyndŵr as he is spelt in Welsh.
The Guardian journalist who contributed it is keen to use the Welsh form of his name, but unfortunately writes it Owain Glyndwyr, not once but twice. So far this error hasn’t been corrected on the website….
In the last paragraph of yesterday’s blog I mentioned the language Ju|’hoan (or Ju|’hoansi). I was interested to note that someone then referred to it in a comment as Jul’hoansi.
Do you get the difference? The third letter in the name of the language is the Unicode character U+01C0, LATIN LETTER DENTAL CLICK. It is not, as vp interpreted it, a lower-case L (U+006C LATIN SMALL LETTER L).
It is very easy to see how confusion may arise. In some fonts the two letters look identical. Here’s the heading of the Wikipedia article, as rendered on my computer screen. But if I copy and paste the first few words of the article into Word, and change the font to Times New Roman, I get this.
But if I copy and paste the first few words of the article into Word, and change the font to Times New Roman, I get this. So in the Arial of Wikipedia the click letter looks identical to a lower-case L. In Times New Roman they are properly distinguished.
So in the Arial of Wikipedia the click letter looks identical to a lower-case L. In Times New Roman they are properly distinguished.
It gets worse. In some sanserif fonts the upper-case letter i (U+0049 LATIN CAPITAL LETTER I) can appear identical to the lower-case L. This makes it difficult to read a word such as illicit if it appears at the beginning of a sentence, or Illyria anywhere.
And here’s a confession: in my blog I actually typed the click letter in the language name not as U+01C0 LATIN LETTER DENTAL CLICK but as U+007C VERTICAL LINE, which can be entered directly from a UK PC keyboard.
Back in the old days of mechanical typewriters many machines lacked the figure 1, so that we had to use a lower-case L in its stead. Fortunately nowadays all computers and most (all?) fonts distinguish them.
I thought it would be worth exploring how well-known fonts handle these differences. Here is what my screen displays for figure 1 (U+0031 DIGIT ONE), upper-case i, lower-case L, vertical line, and click, in the five fonts named.  You can see that Arial is easily the worst, presenting all three alphabetic letters identically. Only Times New Roman and Courier New render all five differently.
You can see that Arial is easily the worst, presenting all three alphabetic letters identically. Only Times New Roman and Courier New render all five differently.
And then there are І (U+0406 CYRILLIC CAPITAL LETTER BYELORUSSIAN-UKRAINIAN I), Ӏ and ӏ (U+04C0 and U+04CF, CYRILLIC LETTER PALOCHKA and CYRILLIC SMALL LETTER PALOCHKA), ׀ (U+05C0 HEBREW PUNCTUATION PASEQ), Ⅰ (U+2160 ROMAN NUMERAL ONE), ∣ (U+2223 DIVIDES), and ❘ (U+2758 LIGHT VERTICAL BAR). Let’s not even go there.
Moral? It is a great pity that in its 1989 symbol reforms the IPA abandoned its distinctive and unmistakable dental click letter ʇ for this confusing vertical line.
There were press reports last week that “a researcher analyzing the sounds in languages spoken around the world has detected an ancient signal that points to southern Africa as the place where modern human language originated.”
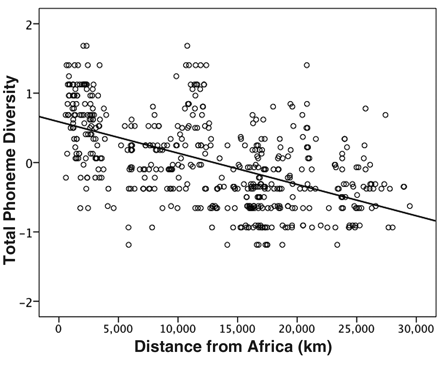
This relates to an article in Science by Quentin D. Atkinson, an evolutionary psychologist/anthropologist from the universities of Auckland and Oxford. His claim can be summed up as: The more phonemes a language has, the closer it is to the putative origin of human language, in Africa. The fewer phonemes it has, the further away from Africa along the track of presumed human settlement: Africa – Eurasia – America and Oceania. Human genetic and phenotypic diversity declines with distance from Africa, as predicted by a serial founder effect in which successive population bottlenecks during range expansion progressively reduce diversity, underpinning support for an African origin of modern humans. Recent work suggests that a similar founder effect may operate on human culture and language. Here I show that the number of phonemes used in a global sample of 504 languages is also clinal and fits a serial founder–effect model of expansion from an inferred origin in Africa. This result, which is not explained by more recent demographic history, local language diversity, or statistical non-independence within language families, points to parallel mechanisms shaping genetic and linguistic diversity and supports an African origin of modern human languages.
Before we go any further, let me refer you to the excellent discussion of this topic that Mark Liberman has just contributed to Language Log, a discussion which I would urge you to read. He queries the bizarre metric used by Atkinson, which means inter alia that ‘losing a single tone would generally reduce "Total Phoneme Diversity" by as much as losing about 10 consonants would’. Atkinson also ignores syllable structure differences and what they imply.
Nevertheless, Atkinson’s claim is interesting and thought-provoking. 
Atkinson’s claim relates to large-scale families of languages rather than to individual languages or dialects. While it may or may not be justified as a generalization on this macro scale, it clearly does not work in specific cases on a micro scale, as can be seen from the considerable scatter around the trend line on his diagram.
Russian has more phonemes than Polish. Portuguese and Catalan have more than Spanish. Marathi has more than Hindi. In none of these cases does it correlate with being closer to Africa.
But yes, Ju|’hoan in Namibia, with four tones, 30+ vowels and 89 consonants (including 48 clicks) easily beats Hawaiian with its parsimonious eight consonants and five vowels.
 I live in a road called Poplar Road. You wouldn’t believe how often people misspell the name of the road as “Popular”.
I live in a road called Poplar Road. You wouldn’t believe how often people misspell the name of the road as “Popular”.
Poplar is pronounced ˈpɒplə. Popular is ˈpɒpjʊlə or more casually ˈpɒpjələ, and as far as I know it is not normally compressed to a bisyllabic form (except perhaps in Norfolk or south Wales). On the other hand city dwellers may be astoundingly ignorant about the names of trees and other plants, and some perhaps don’t know that a poplar is a kind of tree. So they hear this unfamiliar word as the familiar popular.
Our road was once graced by a row of tall and stately poplars. Sadly, the last one remaining was felled a few years ago.
Here’s an exchange on Facebook that was picked up by the icanhascheezburger site.
Another word in which people often epenthesize an extra vowel is athlete. The standard pronunciation, following the spelling, is ˈæθliːt. But an awful lot of speakers break up the medial consonants with a schwa, thus ˈæθəliːt. In LPD I give this version a warning triangle.
The same applies to athletics, triathlon, etc. And people then spell them wrong, too.

Just yesterday I heard a television newsreader announce a breakthrough in the treatment of ˌɑːθəˈraɪtɪs (arthritis). I’ve given that one a warning triangle in LPD, too.
Why do medial θl, θr present a problem? There are plenty of cases where we have these sequences across a morpheme or word boundary: heathland, both lanes, hearthrug, death report and so on, and for AmE with love, with respect etc. And θr is a perfectly ordinary initial cluster: three, thrust, through. No one finds it necessary to apply svarabhakti / anaptyxis / epenthesis in these cases, so why in athlete and arthritis?
 This was a tricky one. A master’s student from Chile wrote
This was a tricky one. A master’s student from Chile wrote
I'm currently working on the theoretical framework for my final research work which is entitled "The glottal stop and its emphatic function in word-initial prevocalic position." At the moment, my attention is focused on endeavouring to validate this emphatic function.
For this purpose, I've been trying to observe other phonetic, phonological, syntactic and semantic features that have been proved to have an emphatic function; one of them most certainly has to do with intonation. I've been reading your book on English Intonation, which I must say is a must, and there's a point in the introduction I would like to ask you about: on page 7 you write, when referring to tonicity, that "speakers use intonation to highlight some words as important for the meaning they wish to convey. These are the words on which the speaker focuses the hearer's attention. To highlight an important word we accent it." One conclusion I think we may draw from this is that accented words then may be considered as "emphasis-carriers".
Later on the same page, you write that the most important accent in the IP is the nucleus. This would mean, as far as I understand, that the word which contains the nucleus is a word that carries more emphasis than the other accented words.
Even later on that page you write that the nucleus "indicates the end of the focused part of the material." Do you consider it would be correct to conclude then that emphasis is carried by the portion of the intonational phrase that goes from the first ("regularly") accented syllable to the nucleus? Which part of that portion would you consider to carry the greatest degree of emphasis? Although I believe I have an answer to that question (the syllable that contains the nucleus of course, and, to a lesser degree, the other accented syllables) it would be really important for me to have your most valuable opinion on this matter.
I’m afraid it took me a little time to reply. Here’s what I eventually said.
As I understand it, 'emphasis' is a pragmatic concept. Its relationship to prosodic features is complex. Perhaps the most difficult point is: do you agree with me that many utterances are wholly unemphatic?
Impressionistically, I would expect that emphasis might typically involve deviating from the unemphatic norm by, for example, one or more of the following:
1. widening the pitch range on the nucleus
2. using a higher pitch range throughout
3. increasing the volume (loudness)
4. using a high prehead rather than the unmarked (low) prehead
5. reinforcing initial vowels by a glottal stop ('hard attack')
etc.
From what I write in the book English Intonation you want to conclude that "accented words may be considered as emphasis-carriers" and "the word which contains the nucleus is a word that carries more emphasis than the other accented words". I disagree, though obviously it depends on how you define emphasis. If you agree with me that many utterances are unemphatic (have no emphasis), then it is wrong. If you believe that all utterances include some degree of emphasis, then I suppose it is arguably true. But you would merely be relabelling accent as emphasis.
You must take my words in English Intonation at their face value. [...] All of what I say there applies basically to what I consider to be unemphatic speech. Every IP requires that certain syllables be accented, independently of whether anything is emphasized. For me, accentuation is not the same thing as emphasis.
I hope this is helpful.
 For our summer show the LGMC in which I sing is presenting an “aural adventure” called Sound and involving music in a wide variety of styles from a wide variety of places (blog, 4 March).
For our summer show the LGMC in which I sing is presenting an “aural adventure” called Sound and involving music in a wide variety of styles from a wide variety of places (blog, 4 March).
On Monday the composer Orlando Gough joined us to teach us his piece Olympic Hopefuls. This could be called a soundscape of human noises, and involves our unaccompanied singing of a text mostly consisting of nonsense syllables, with occasional strings of real (English) words that nevertheless are not included in any kind of grammatical sentence structure.
Sample text:home bam bee put ho n kit chi koo a
dut sko mee ney har do vee dey
… four five ring fence post box ticking
I suppose you could call the piece an a cappella tone poem.
The score contains frequent musical or choreographic directions to the singers: ‘keen, breathy’, ‘slurred, out to lunch’, ‘tribal’, ‘hit chest (hard)’, ‘knackered, panting’, ‘deeply charismatic’ and many others. A paralinguistic feast.

 Helpfully, the composer has provided a key to interpreting the spellings of the nonsense syllables. As you can see, the repertoire of vowels comprises just these nine: æ e ɪ əʊ ʌ aɪ ə ɑː eɪ. Schwa is always difficult to respell. I assume that the singers all know that hookah is ˈhʊkə. In interpreting the instruction “single consonant: add schwar” I think the composer means ə, not an AmE-style ɚ. We’ve just got to live with the fact that where the composer writes har most of the choir pronounce hɑː, as he does himself, but that the few choir members who are Scottish or American inevitably go for hɑːr.
Helpfully, the composer has provided a key to interpreting the spellings of the nonsense syllables. As you can see, the repertoire of vowels comprises just these nine: æ e ɪ əʊ ʌ aɪ ə ɑː eɪ. Schwa is always difficult to respell. I assume that the singers all know that hookah is ˈhʊkə. In interpreting the instruction “single consonant: add schwar” I think the composer means ə, not an AmE-style ɚ. We’ve just got to live with the fact that where the composer writes har most of the choir pronounce hɑː, as he does himself, but that the few choir members who are Scottish or American inevitably go for hɑːr.
I started off somewhat sceptical about this composition. But as we practised it I grew convinced that it will make an impressive, if unusual, item in the concert.
Orlando’s surname, Gough, is pronounced ɡɒf and is of Celtic origin. In some cases it represents Scottish Gaelic gobha, Cornish or Breton goff, ‘smith’. In other cases it derives from the Welsh goch ɡoːχ, the soft-mutated form of coch ‘red’.
Gosh, I only have to turn my back for a moment and we end up with 75 comments posted in response to my most recent blog (7 April). Most of the comments have nothing to do with my topic, which was Scottish vowels. And none of the commentators so much as mention the classifications sociolinguists commonly make involving ausbau languages, abstand languages and umbrella languages. Can I recommend that those interested read this article before commenting further?
_ _ _
 Someone signing himself just Hammer writes as follows.
Someone signing himself just Hammer writes as follows.
I have a question about the pronunciation of /s/.
Most of the books on phonetics describe that "the tip and blade of the tongue are very close to the alveolar ridge" (Better English Pronunciation, J.D. O'Connor). However, I found it is hard for me to articulate a decent /s/. (Maybe it's because I'm a little buck-toothed?) Instead, I found the "alternative method" is much easier, that is, place the tip of the tongue behind the bottom teeth.
I would like to thank you very much if you could tell me:
1) Do you think the "bottom teeth" method is correct?
2) Do you regard the "bottom teeth" method as "having an accent"?
3) I find that some native English speakers also adopt the "bottom teeth" method. If that is true, could you please tell me what percentage of people actually saying hat way. I do like your Preference Poll method.
4) What are the pros and cons of these 2 methods, and why?
I would describe (my) English s as being articulated by the BLADE of the tongue rather than by the tip. The side rims of the tongue are in close contact with the upper teeth or the adjacent gums and roof of the mouth, so that there is no lateral escape. The soft palate is up, so that there is no nasal escape. The important point is that the tongue adopts a posture involving a narrow mid-sagittal GROOVE between the tongue and the alveolar ridge (‘mid-sagittal’ = running along the centre of the tongue, from back to front). All the escaping air is channelled along this groove. The effect is to cause turbulence in the airstream, with the auditory consequence of producing the noise of friction as it passes along the groove and strikes the upper teeth. The palatogram you see (taken from the current edition of Cruttenden/ Gimson's Pronunciation of English) shows the groove clearly, as white spots of non-contact.
Since the tip and blade are contiguous, with no sharply defined border between them, it is trivially true for all kinds of s that “the tip and blade are very close to the alveolar ridge”.
It is also necessary that the lower jaw is quite close to the upper jaw. (If you lower the jaw and try to produce s with it in that position you’ll find that you can’t — not a normal s, anyway.)
There are minor differences in anatomy between different speakers. What matters is not this or that exact anatomical positioning of the tongue so much as the creating of the appropriate sound effect — friction at the appropriate range of frequencies (3.6–8kHz).
Experimenting with the position of the tongue TIP in (my own) s, I find it doesn’t seem to matter much, because it is not the active articulator. It merely has to keep out of the way.
Bladon and Nolan, in their 1977 article ‘A video-fluorographic investigation of tip and blade alveolars in English’ (JPhon 1: 185-193), found that most speakers articulate s with the blade (‘laminal’) rather than with the tip (‘apical’).
In many other languages s is apical. Does it matter if you use a ‘foreign’ s in English? As long as you keep s clearly distinct from θ in one direction and from ʃ in the other, I suspect that subtle distinctions in the quality of s are not very important for EFL.
To answer Hammer’s questions in order:
1. It is irrelevant where the tongue tip is in relation to the bottom teeth. I think you are really asking about laminal s vs apical s, i.e. which part of the tongue articulates with the alveolar ridge.
2. No — see 1.
3. I don’t know (but see Bladon and Nolan). I don’t think people responding to a questionnaire would be able to report accurately on what they do in this regard, so I wouldn’t ask them.
4. I hope what I have said above answers the question you are worried about.
Here is an interesting graphic created by Jim Scobbie at QMU Edinburgh. It shows ‘a typical Scottish vowel system, single tokens from one speaker’, as revealed by ultrasound tongue imaging. 
We know that the vowel system of Scottish English is rather different from the vowel systems of all other kinds of English (except northern Irish, which has historical links with it). Most striking is the absence of the FOOT-GOOSE opposition that is found in all other varieties of English. In Scottish English, good rhymes with mood, look is a homophone of Luke, and put rhymes with shoot. All have the same close vowel, phonetically somewhere in the range u - ʉ - y.
(For some reason the Co-op decided to use a Scottish actor to utter the payoff line good with food at the end of each of their current series of television ads. For example, right at the end here.)
There is also typically no opposition between LOT and THOUGHT or between TRAP and PALM. So cot and caught are likely to be homophones kɔt (as in many other kinds of English, though not in England), and so are Sam and psalm sam.
This gives the vowel system i ɪ e ɛ a ʌ u o ɔ shown in Scobbie’s plot. It is striking that it shows ɪ as lower than ɛ, with u just as front as i. (NB: the lips are to the right, differently from our usual vowel charts.)
There are no intrinsically long vowels in the Scottish system, although some vowels undergo lengthening when morpheme-final or when followed by v, ð, z, r (the ‘Scottish Vowel Length Rule’ or Aitken’s Law). In particular, vowels are short before d, which means that the vowel in Scottish need sounds shorter than that in English need, though the quality is still tense i. If we take the verb to knee, however, its past tense kneed has a long vowel because of the morpheme boundary. Thus we have a minimal pair nid – niːd. Other comparable pairs are brood – brewed and tide –tied. Try side and sighed on your Scottish friends: they will typically be amazed that non-Scots do not distinguish between them.
Scottish English varies from place to place and class to class, and Scots (language/dialect) even more. Here’s a clip of fishermen in Cromarty talking about the loss of their special vocabulary. (Thanks, Amy Stoller, for this.)
This clip is also notable for the placename Avoch. As you can hear, the speaker calls it ɔx. I didn’t put the name of this tiny village in LPD, though EPD has it, as ɔːx, ɔːk. Wikipedia transcribes the name ɒx, and has a sound clip. Since there is no LOT-THOUGHT opposition in Scottish English, it is pointless to argue which of the two is correct.
_ _ _
I shall be busy at a conference over the next few days. Next posting: 12 April.
 Why does English r have such a strong labial component?
Why does English r have such a strong labial component?
Despite Gimson’s claim in his Pronunciation of English, retained by Cruttenden (p. 220 in the seventh edition, 2008), that The lip position is determined largely by that of the following vowel
nevertheless I am sure that I am not alone in lip-rounding initial r in read and rest just as in root and raw.
I have found that I can often improve English speakers’ pronunciation of Spanish or Italian r by getting them to get rid of the lip-rounding of this consonant that they wrongly carry over from English to the target language.
Where does this labiality come from?
Rohan Dharwadkar asks Does the secondary labialisation of the RP R have anything to do with the loss of the labio-velar approximant in initial 'wr' sequences in words like 'write', 'wring', etc.?
My impression is that the R-labialisation is a relatively recent change, whereas the 'w's in question have been silent for a lot longer. And yet, for R to take on labialisation with no apparent trigger seems whimsical (which I realise languages very often are, but still.).
It’s an attractive idea, and one that I think has been floating around for some time, though I can’t put my hand on any discussion of it in the literature.
The OED, under the letter W, has a long discussion of “The combination wr”. Here’s a fragment. Signs of the dropping of the w begin to appear about the middle of the 15th cent. in such spellings as ringe for wring v., rong for wrong adj.; these become common in the 16th cent. (for examples see wrangle n., wrap n., wreak n., wreck n.1, wrench n.1, wrest n.1, etc.). Reduction of the sound is also indicated by the converse practice of writing wr- for r-, which similarly appears in the 15th cent. (in wrath for rathe), and becomes common in the 16th; for examples see the subordinate entries under wrack n.1, wracked adj., wrap n., wretchless adj., etc. In standard English the w was finally dropped in the 17th century.
Pairs such as wring – ring, write – right, wrap – rap are homophonous in all kinds of modern English. Yet until a few hundred years ago they were distinct, the first in each pair having a labialvelar component and the second lacking it. Is it plausible that as the distinction disappeared it was the labialvelarized variant that became generalized, so giving us our modern labialized r?
Some idiosyncratic speakers take matters further. Gimson/Cruttenden again (p. 221): some speakers labialize /r/ whatever the following vowel. In extreme cases, lip-rounding is accompanied by no articulation of the forward part of the tongue, so that /r/ is replaced by /w/ and homophones of the type wed, red are produced. Alternatively a labiodental approximant [ʋ] may be heard as a realization of /r/ or even for both /r/ and /w/. Pronounciations [sic] of this sort were a fashionable affectation in the nineteenth and early twentieth century; and can still be heard as such from some elderly people educated at major public schools.
I don’t know what evidence there is for accusing those who do this of a ‘fashionable affectation’. None, I suspect.
The Guardian’s parliamentary sketch writer Simon Hoggart regularly lampoons Sir Peter Tapsell MP for his supposed use of /w/ for /r/. Here he is recently. Sir Peter Tapsell had made one of his stupendous interventions, calling for "the complete sepawation" (Sir Peter has a slight speech impediment) of commercial and investment banks.
I doubt very much that Sir Peter actually confuses /r/ and /w/. He does use [ʋ] for /r/, though. Listen here and judge for yourself.
 In a PS to an email he sent me Jack Windsor Lewis said, gnomically,
In a PS to an email he sent me Jack Windsor Lewis said, gnomically, LPD Welsh items "sd" involves fortis and lenis paired in a syllable onset. Is this feasible and if so what other language does it?
I replied, equally gnomically, Welsh [sd] is by analogy with [sb] and [sg] reflected in the spelling. The plosive is unaspirated in this environment.
So what’s this about?
In LPD I give the Welsh-language pronunciation of Aberystwyth as a ber ˈə sduɨθ. In English, on the other hand, it is ˌæb ə ˈrɪst wɪθ. Jack wants to know why I transcribe the last syllable in the Welsh form with sd rather than st.
Behind this decision there is a chain of reasoning.
In Welsh spelling the sequences sb and sg are often encountered: for example, cosb ‘punishment’, hysbysiad ‘announcement’, sbwriel ‘rubbish’; rhwysg ‘pomp’, dysgu ‘teach, learn’, sgwd ‘cataract’. English spell ‘period of time’ is Welsh sbel; English score is Welsh sgôr. As far as I can recall there are no words in Welsh spelt with sp or sc. (There is inconsistency in Anglo-Welsh placenames: Skewen appears also as Scuan, Sgiwen etc; Welsh Ynysgynwraidd gives English Skenfrith.)
It is a commonplace to point out that in English (and various other languages) the opposition between the voiceless/fortis series p t k and the voiced/lenis series b d g is neutralized after s. The putative p in English spin is typically unaspirated — like b but unlike most other cases of p. Every now and again someone has the idea of arguing that this word should correctly be transcribed as sbɪn rather than spɪn. The same applies with the initial clusters in stop (sdɒp?) and skip (sɡɪp?).
If someone wants to transcribe English this way, I find it difficult to argue forcefully against the idea. And even when the s and the plosive are putatively in different syllables there may be something very close to a neutralization: think about discussed and disgust.
A fortiori, in languages such as Welsh, Scottish Gaelic, or Icelandic, where the main distinguishing feature between the two plosive series appears to be aspiration rather than voicing, the analysis as sb sd sg seems justified.
Inconsistently, though, at the alveolar place Welsh spelling has st rather than the sd you might expect. We have tyst ‘witness’, llestri ‘dishes’, straeon ‘stories’, while English strike is Welsh streic. But phonetically these clusters correspond exactly to those with the bilabial and velar plosives, so it is only logical to analyse them the same way.
Ball and Williams, in their Welsh Phonetics (Lampeter: Edwin Mellen, 2001), p. 99, found a VOT of 12ms for /sb/, 20ms for /sd/, and 29ms for /sg/. For comparison, /b/ has 15ms but /p/ has 62ms, /d/ 33ms, /t/ 82ms, /g/ 32ms, /k/ 97ms. They conclude These results show clearly that in terms of the aspiration feature, the feature that carries the main acoustic cues for the distinguishing of the fortis stops from the lenis, these stops in /s/-clusters should be classified as lenes, as shown in the recommended transcription […] /sb, sd, sg/.
Jack also asks “what other language does it?”. Here’s a scan from a book on Icelandic phonetics (Árni Böðvarsson, Hljóðfræði, Reykjavík 1979).  I assume that fráblásturslaus means ‘unaspirated’.
I assume that fráblásturslaus means ‘unaspirated’.
Before someone points it out, I immediately concede that for consistency in LPD I ought to have transcribed the Welsh pronunciation of Llanrwst as ɬanˈruːsd rather than what I actually put, ɬanˈruːst. Ach-y-fi!
 Ernesto L .B Sastre wrote
Ernesto L .B Sastre wrote
I hope you can help me with this matter about phonetics. I couldn't prove that there actually existed progressive assimilation for /s/ to become /ʃ/. […]
I have been doing some online research about it, but didn't manage to find anything about it. I also asked around, but it was denied that there existed such assimilation. Your dictionary also states that there [is] only regressive assimilation.
Nevertheless , the notes I was given by my Phonetics teacher included this type of assimilation. Here is an example of it:
bookish style /bʊkɪʃ staɪl/. If there is assimilation: /bʊkɪʃ ʃtaɪl/
Have you ever heard of this before?
No, I haven’t. My immediate reaction was that this type of assimilation simply doesn’t happen. That’s why Ernesto can’t prove that it does, and also why he can find no reference to it in his on-line search.
However, phonetic research is not just a matter of finding out what published descriptions say about this or that phenomenon (in this case, they seem to say nothing). Genuine research involves making observations: observing and analysing what speakers actually say. I told Ernesto he should
Collect some evidence, and see what you find.
The phonetic context we are interested in is by no means unusual. Plenty of possible examples come to mind.
British citizen
cash some cheques
cash-strapped shoppers
crash site
wash six pairs of socks
horseradish sauce
fish soup
rush suddenly
push something
Does anyone know of any research into the phonetics of such ʃs sequences?
Introspecting, I feel pretty confident in saying that full-blown progressive (= perseverative) assimilation, thus ˈbrɪtɪʃ ˈsɪtɪzn̩ → ˈbrɪtɪʃ ˈʃɪtɪzn̩, just doesn’t happen. Nor does full-blown regressive assimilation, thus ˈbrɪtɪs ˈsɪtɪzn̩. However some kind of intermediate allophonic regressive assimilation, perhaps ˈbrɪtɪɕ ˈsɪtɪzn̩ or somethinɡ similar, seems possible.
I stick by my view that in English progressive assimilation is restricted to
(i) morphological assimilation of voicing, producing s in cats and t in kissed (compare dogs with z and raised with d); there are also possible one-off cases such as newspaper and (pre-decimal) fivepence; furthermore there is also allophonic assimilation of voicing, always in the direction of voicelessness; and
(ii) assimilation of syllabic n̩ to the place of a preceding obstruent, as in ribbon (ˈrɪbən →) ˈrɪbn̩ → ˈrɪbm̩.
I think Ernesto’s phonetics teacher was wrong. In English phonology, features typically spread leftwards, not rightwards.
Faute de anything mieux with which to celebrate April Fool’s Day, here is an example of … er, cack-handed misspelling of Welsh. It shows a street name erected by the local council in Conwy borough in north Wales, and is taken from a blog entry whose Welsh title translates as ‘A nasty smell at the Junction” (that is, Llandudno Junction). The first line, GWEL YR AFON, is the name of the road, “River View”. The second ought to be FFORDD BREIFAT, “private road”, i.e. a road for the maintenance of which the local council does not accept responsibility.
The first line, GWEL YR AFON, is the name of the road, “River View”. The second ought to be FFORDD BREIFAT, “private road”, i.e. a road for the maintenance of which the local council does not accept responsibility.
To simplify the sociolinguistic demographics somewhat, we can say that Conwy borough combines an English-speaking urban centre with Welsh-speaking outlying villages. There had been complaints about the number of English-only street signs and road names.  The Welsh word preifat ‘private’ shows by its form that it is the English word ˈpraɪvət respelt in accordance with Welsh spelling conventions (f = v). In the sign, the initial consonant is correctly mutated to b-, to agree with the feminine noun ffordd fɔrð ‘road’.
The Welsh word preifat ‘private’ shows by its form that it is the English word ˈpraɪvət respelt in accordance with Welsh spelling conventions (f = v). In the sign, the initial consonant is correctly mutated to b-, to agree with the feminine noun ffordd fɔrð ‘road’.
If this word had been borrowed into Welsh direct from Latin prīvātus 1800 years ago when the Romans were in Britain, as were such words as pont ‘bridge’, llafur ‘labour’ and ffenest ‘window’, I think it would probably have come out as something like prywod. (Compare parātus → parod ‘ready’.) But obviously it wasn’t. It came via English.
The person who created the road sign knew sufficient Welsh to do the correct mutation. But he or she was English enough to confuse the digraphs ei and ie and to produce a fine example of non-rhotic hypercorrection. As it stands, the sign regrettably suggests that the road is characterized by flatulent cheese-eaters.
 Harry Campbell asked
Harry Campbell asked 





























{kind=link}