This relates to an article in Science by Quentin D. Atkinson, an evolutionary psychologist/anthropologist from the universities of Auckland and Oxford. His claim can be summed up as: The more phonemes a language has, the closer it is to the putative origin of human language, in Africa. The fewer phonemes it has, the further away from Africa along the track of presumed human settlement: Africa – Eurasia – America and Oceania.
Human genetic and phenotypic diversity declines with distance from Africa, as predicted by a serial founder effect in which successive population bottlenecks during range expansion progressively reduce diversity, underpinning support for an African origin of modern humans. Recent work suggests that a similar founder effect may operate on human culture and language. Here I show that the number of phonemes used in a global sample of 504 languages is also clinal and fits a serial founder–effect model of expansion from an inferred origin in Africa. This result, which is not explained by more recent demographic history, local language diversity, or statistical non-independence within language families, points to parallel mechanisms shaping genetic and linguistic diversity and supports an African origin of modern human languages.
Before we go any further, let me refer you to the excellent discussion of this topic that Mark Liberman has just contributed to Language Log, a discussion which I would urge you to read. He queries the bizarre metric used by Atkinson, which means inter alia that ‘losing a single tone would generally reduce "Total Phoneme Diversity" by as much as losing about 10 consonants would’. Atkinson also ignores syllable structure differences and what they imply.
Nevertheless, Atkinson’s claim is interesting and thought-provoking.
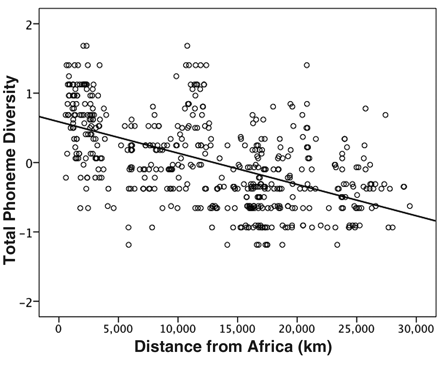
Atkinson’s claim relates to large-scale families of languages rather than to individual languages or dialects. While it may or may not be justified as a generalization on this macro scale, it clearly does not work in specific cases on a micro scale, as can be seen from the considerable scatter around the trend line on his diagram.
Russian has more phonemes than Polish. Portuguese and Catalan have more than Spanish. Marathi has more than Hindi. In none of these cases does it correlate with being closer to Africa.
But yes, Ju|’hoan in Namibia, with four tones, 30+ vowels and 89 consonants (including 48 clicks) easily beats Hawaiian with its parsimonious eight consonants and five vowels.






Isn't there a strong positive correlation between size of phoneme inventory and number of speakers? Global languages tend to have a larger phoneme inventory than the languages of small, isolated tribes?
ReplyDeleteObviously the languages of the far South of Africa don't conform to this pattern, Khoi-San languages in particular having extremely rich consonant inventories, along with their immediate Bantu neighbours.
But presumably the researchers have corrected for this tendency?
Interesting article.
ReplyDeleteAs a self-taught student of linguistics, I have noticed that the number of phonemes in languages does tend to decline as one moves away from Africa, though there are major exceptions in the Himalayas and the northwest of North America.
However, if you study carefully, one will see very different trends with consonant and vowel phonemes. The number of vowel phonemes shows a very consistent negative relationship with morphological complexity, as can be seen broadly here. Highly analytic languages always have large vowel inventories, since highly marked vowel phonemes are more likely to survive in isolated words, whilst highly polysynthetic head marking languages generally have two or three vowels only (sometime with allophonic variation).
The number of consonant phonemes, on the other hand, shows large-scale areal clustering for which a causal link is not easy to see, and where the actual clustering is sub-continental.
@Anonymous - yes, they've corrected for the correlation between phoneme inventory size and speaker population. But if you read Mark Lieberman's LL article you'll see he raises more serious questions about counting phonemes cross-linguistically.
ReplyDeleteBut I can't work out how they get the implication "more phonemes" -> "more ancient human presence". There seems to be some analogy with the established implication "greater genetic diversity" -> "more ancient human presence" but I can't see it, and the paper requires a subscription.
There's lots more discussion on the paper on Language Log - maybe someone's broken it down there...I suppose everyone's scouring LL as I type; hence the silence...
It's a difficult question. It depends on how one interprets the concept of a phoneme. As I understand a phoneme makes a difference in meaning (whatever its exact surface realization is). I believe meaning is bound to an entire language, not to single dialects -- otherwise speakers of different dialects wouldn't understand each other. But if meaning and phonemes are related, I'd expect phonemes to be bound to a language, too, rather than to individual dialects. In other words: all dialects of a language should have the same phoneme inventory.
ReplyDeleteIf this is correct, how can one talk about different phoneme inventories in AmE vs. BrE? How can one talk about a phonemic merger (e.g. cot-caught) in one dialect that is not found in another?
If this is wrong, what does one base their survey on? The phoneme count of which dialect of English or any other language is taken?
@teapdrop: I don't think it's correct to say that phonemes are bound to language and not to dialect (assuming you mean by that that two dialects of the same language can't have different phoneme inventories). For example, the vowel inventories of English dialects vary wildly due to splits like FLY-TRY and TRAP-BATH, and mergers like COT-CAUGHT and FORCE-NORTH. So different dialects (i.e. mutually-intelligible varieties) of the same language can definitely have different phoneme inventories.
ReplyDeleteI wouldn't necessarily say meanings are bound to whole languages rather than dialects either (assuming you mean that the meaning of a word in one dialect is the same as the meaning of the same word in a different dialect of the same language). For example, in Ireland to nurse means "to cuddle or stroke (as one might a dog or someone else's baby)", while in England it means "to breastfeed"! And of course many sartorial terms such as pants and vest have different meanings between US English and British English.
I'd say if two dialects have the exact same phoneme inventory and the exact same meaning to every word, then they're pretty much the same dialect. Speakers of different dialects can still understand each other as long as they avoid using such terms in confusing ways.
What is a phoneme?
ReplyDeletePete: They might still be distinct at the phonetic level. AusE and RP have a very similar if not identical pattern of lexical-set mergers, but impressionistically no one would mistake one for the other. (Except for iggerant Yanks, of course.)
ReplyDeleteMarathi has more than Hindi. In none of these cases does it correlate with being closer to Africa.
ReplyDeleteThe Marathi-speaking area is closer to Africa, as the crow flies, than the Hindi-speaking area. By land they are approximately equidistant from Africa, unless one counts Rajasthani as Hindi, in which case Hindi is closer by land.
I just took a look at Jul'hoansi. My goodness! Does one need to be able to demonstrate e.g. the distinction between a uvularized click and an epiglottalized click in order to be a professional phonetician?
ReplyDelete@John Cowan: I thought someone might say that! Yes, you're right, of course: two people can have the exact same set of phonemes but realise each one differently without splits or mergers; I'd call that two accents.
ReplyDeleteAnd similarly, for two dialects to be the same it's probably not enough to have the same phoneme inventory and the same vocabulary, as discussed above; you'd also want to have the same grammar. But if all words have the same meaning then does that not imply they're used in the same way as well? And therefore the grammar is the same? I wouldn't like to stake my reputation on this reasoning to be honest, but I'd be hard-pressed to think of two dialects with exactly the same phoneme inventory and exactly the same vocabulary btu different grammar.
It's pretty academic anyway. I was just making the point that dialects of a single language normally do differ in their phoneme inventories and the meanings they attach to words, and that this doesn't necessarily impede mutual comprehensibility. In fact it can't impede mutual comprehensibility, by definition of "dialect" - because if the dialects are mutually incomprehensible then they're different languages.
We're off topic here though...
But if you read Mark Lieberman's LL article you'll see he raises more serious questions about counting phonemes cross-linguistically.
ReplyDeleteFor instance, such questions decide whether Hawai'ian should be counted as having 5 or 10 vowel phonemes and Juǀʼhoan as having over 30 or perhaps just 5 or maybe 9. And if some of the more complex clicks are interpreted as consonant clusters...
@David
ReplyDeleteYes; which is why I think number of distinctive syllables would be a much better measure than number of distinctive phonemes. This would take into account clustering and positional constraints on phonemes. There would still be disagreement as to whether a given words should be analyzed as two syllables with hiatus or one with a diphthong, but the scope of disagreement would be greatly reduced.
Actually, in some languages, different ways to draw the boundaries between syllables would probably lead to different syllable counts.
ReplyDeleteOne example are the ambisyllabic consonants of southern German: if you accept those (as I do for at least two reasons), you get for instance syllables (not words, but still syllables) beginning with [ŋ] smack dab in the middle of Europe – in southern Standard German but not in the phonologically just about identical and phonetically very similar central and northern Standard German accents.
In Serbocroatian, the orthographers simply gave up and allowed both ze-mlja and zem-lja as syllable separations. (Lj is a single sound and is even considered a single letter.)
Our esteemed host has often mentioned different ideas on how best to interpret syllable boundaries into English words and has recently alluded to similar uncertainties existing in Welsh.
But how many such languages are there? Certainly fewer than those where all phonemic vowel qualities can be phonemically long or short, right?
I read an article about this research a few days ago, and there was something that immediately made me feel skeptical about the data he used: from a diachronic point of view, how can his theory be justified? Languages often create or eliminate phonemes over time; Spanish, for instance, has nowadays palatal consonants that didn't exist in Latin, and this may have happened in African languages as well.
ReplyDeleteWhat bothers me about this, and the earlier study of the Indo-European 'family tree' is that the mathematics is based on what happens in genetics. But languages can partly recombine after a split, while genetic mutations continue to be reflected for ever — or until the next mutation.
ReplyDeleteSuch things happen in genetics, too. Incomplete lineage sorting... lineage fusion... oh, and good old convergence. They don't matter in the long run, and there are methods to discover them and deal with it where they do matter (or are the very subject of the study).
ReplyDeleteForgive me but I have this strange urge to call this a nutty, untestable theory. I guess it's because I accept as fact that modern phonological systems have absolutely no bearing on any Adam-and-Eve "First Tongue" one might envision some hundreds of thousands of years before present.
ReplyDeletePete,
ReplyDeleteif phoneme count depends on dialects rather than languages, why does this survey seek the correlation between the phoneme inventories of languages and their distances to Africa? From this aspect, a language itself doesn't even have any phonemes, only its dialects do.
The Founder effect explanation seems to rest on the assumption that the original African tongue contained a huge number of phonemes. What justification is there, if any, for such an assumption?
ReplyDeleteI don't think Marathi has more phonemes than Hindi when nasal vowels are counted. Marathi has no nasal phonemes at all!
ReplyDeleteYeah, I'm highly suspicious of Atkinson's work, although it is surely thought-provoking.
ReplyDeleteSome of you may remember his earlier paper, in which he "demonstrated" that Indo-European was incredibly young, by some more bizarre metrics taken straight from biology. It was also printed in Science, altho eviscerated by linguists.
Atkinson is a geneticist, and he keeps massaging linguistic data into theories about genetics. This is a bass-ackwards way of doing research. Of course, there are always links between genetics and language, but they clearly do not work the same: look at global English vs. "Anglo-Saxon DNA" and you'll see what i mean.
Likewise, his fit doesn't work: Spanish has fewer phonemes than Athabascan, yet is clearly much closer to Africa. Sorry, but his theory falls apart pretty quickly when looking at the data.
Also: good point by Uzza-- it annoys me when people assume that the San must speak "ancient languages". Why?
ReplyDeleteOne could find even more arguments in favor of the opposite: that in the periphery in Southern Africa, they were isolated enough to develop complexity over time.
Therefore, perhaps they have more phonemes than most language due to their longer-time developing, rather than their retaining "ancient linguistic features." This is really much for fitting with what we know of linguistics.