skip to main |
skip to sidebar
Commenting on Monday’s blog, Wojciech made the surprising remark Re the symbol 'a' in IPA: I too find it strange that it's reserved for a phoneme which occurs so rarely in European languages (if it occurs at all). Whereas the common continental (and Northern English, methinks) 'a' has got to be transcribed 'ä'.
I say no it isn’t, and no it doesn’t.
The vowel a occurs extremely commonly in European languages (and of course in non-European languages). The Northern English TRAP vowel, too, is very satisfactorily represented by the symbol a, with no diacritics. The contrary claims reveal a basic misunderstanding of how phonetic symbols are used when we represent the phonemes of a language or language variety. Let’s see why.
 The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.
The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.
No language is actually spoken with cardinal vowels: they are idealized reference points not defined by what happens in any particular language. (They are, however, suspiciously similar to a subset of the vowels of standard French as spoken in Jones’s day — though the quality of French ɔ, at least, was and is considerably different from that of cardinal ɔ. In passing we may note that the articulatory-auditory theory behind Jones’s cardinal vowel scheme is no longer accepted.)
Rather, these symbols are used for vowels in the general area concerned. Like all IPA symbols, they allow some considerable leeway. A typical French e is not identical with a typical Italian e or a typical German e, although all share a general similarity and all can be characterized as unrounded, front, and close-mid (‘half-close’). Compare colour terms, where we happily refer to shades of crimson, scarlet, vermilion and so on all as ‘red’. We are dealing not with discrete entities but with points in a multidimensional continuum.
In those languages it so happens that the close-mid e is distinct from an open-mid (‘half-open’) ɛ. (This claim is subject to qualification: for many French speakers the choice of one or the other can be more or less predicted from the phonetic environment, although others distinguish e.g. les le from lait lɛ; not all Italians make the distinction between venti ‘twenty’ with e and venti ‘winds’ with ɛ; in German the vowel quality distinction is accompanied, in stressed syllables at least, by a length distinction.)
There are many other languages in which there is only one unrounded mid front vowel: they include Greek, Spanish, Serbian, and Japanese. Qualititatively this may lie anywhere between cardinal e and cardinal ɛ. In each case the appropriate symbol, though, is e. In the words of the 1949 IPA Principles booklet (§20), When a vowel is situated in an area designated by a non-roman letter, it is recommended that the nearest appropriate roman letter be substituted for it in ordinary broad transcriptions if that letter is not needed for any other purpose. For instance, if a language contains an ɛ but no e, it is recommended that the letter e be used to represent it. This is the case, for instance, in Japanese…
Similarly, the symbol a, which as a cardinal vowel symbol denotes an unrounded front open (low) vowel, is also appropriate to denote an unrounded open vowel of any degree of advancement (anywhere from fully ‘front’ to fully ‘back’) if that is the only open vowel in the language. This is the case in Spanish, Italian, Greek, Serbian, German, and Polish, to mention only a handful of European languages. It is also the case in thousands of other languages around the world.
In RP I say ðə kæt sæt ɒn ðə mæt. If I switch into northern (I was bidialectal as a child), I say ðə kat sat ɒnt mat. That’s how I would transcribe it. I’ll leave someone else to measure the formant values of my northern a to determine just how central it might be.
This is a live issue. The Council of the IPA, having previously failed to agree, is again debating the issue of whether to recognize an additional vowel symbol, A, to represent a quality between cardinals a and ɑ. I shall vote against.
The Guardian has a regular rubric in its Corrections and Clarifications column, Homophone Corner. Yesterday’s read as follows. This led me to wonder what proportion of NSs have illicit (illegal) and elicit (evoke) as categorical homophones. Most of us, for sure. But are there some who make the vowel of elicit tenser than that of illicit? And do they do this variably or categorically?
This led me to wonder what proportion of NSs have illicit (illegal) and elicit (evoke) as categorical homophones. Most of us, for sure. But are there some who make the vowel of elicit tenser than that of illicit? And do they do this variably or categorically?
I ask because this is relevant to the notation appropriate for the Latin prefix e- in English words. As you will be aware, for the third edition of LPD I simplified the notation for the unstressed prefixes be-, de-, pre-, re-, deciding to use the happY vowel i rather than enumerating mainstream ɪ plus variant iː. (In any case we still need the further variant with ə.) I really wasn’t sure whether to include the e- words in this, but eventually decided to.
 Even that decision left marginal cases that were difficult to decide, and for which I may with hindsight have made the wrong decision. Elect? Event? Eleven? Of course, the decision for each particular word must depend not on etymology but on whether there appear to be people who use the tenser vowel — hence the inclusion of eleven, which does certainly not contain Latin e-.
Even that decision left marginal cases that were difficult to decide, and for which I may with hindsight have made the wrong decision. Elect? Event? Eleven? Of course, the decision for each particular word must depend not on etymology but on whether there appear to be people who use the tenser vowel — hence the inclusion of eleven, which does certainly not contain Latin e-.
 It also means that the main pronunciation given for elicit, iˈlɪsɪt, looks different from that for its putative homophone illicit, ɪˈlɪsɪt, which clearly has no tense-vowel variant. (Compare the main prons for descent diˈsent and dissent dɪˈsent, which likewise are homophones for most speakers but I think not all.)
It also means that the main pronunciation given for elicit, iˈlɪsɪt, looks different from that for its putative homophone illicit, ɪˈlɪsɪt, which clearly has no tense-vowel variant. (Compare the main prons for descent diˈsent and dissent dɪˈsent, which likewise are homophones for most speakers but I think not all.)
For previous discussion of the general issue, see my blog for 29 Jan 2007.
kɪdɪŋ ɔː nɒt, ɪf ə kɒmənteɪtər ɒn fraɪdiz blɒɡ kleɪmz tu əv hæd dɪfɪkl̩ti prəʊsesɪŋ ðə hedlaɪn ðen ɪts haɪ taɪm wi hæd ənʌðər entri rɪtn̩ həʊlli ɪn fənetɪk trænskrɪpʃn̩. (ðə lɑːs sʌtʃ entri ɪn ðɪs blɒɡ wəz ɪn dʒuːn.)
 lɑːs naɪt aɪ pleɪd maɪ mələʊdiən ət ə seʃn̩ ɪn ə pʌb ɒn wɪmbl̩dən kɒmən, nɒt veri fɑː frəm weər aɪ lɪv. ðiːz seʃn̩z ə held wʌns ə mʌnθ ən ɔːɡənaɪzd baɪ ə ləʊkl̩ mɒrɪs saɪd.
lɑːs naɪt aɪ pleɪd maɪ mələʊdiən ət ə seʃn̩ ɪn ə pʌb ɒn wɪmbl̩dən kɒmən, nɒt veri fɑː frəm weər aɪ lɪv. ðiːz seʃn̩z ə held wʌns ə mʌnθ ən ɔːɡənaɪzd baɪ ə ləʊkl̩ mɒrɪs saɪd.
dʒʌst ʌndə twenti piːpl̩ tɜːnd ʌp fə ðə seʃn̩. ðeɪ ɪŋkluːdɪd θriː ʌðə mələʊdiən pleɪəz. ɪts ɔːlwɪz ɪntrəstɪŋ tə kəmpeə nəʊts. bifɔː wi stɑːtɪd, wʌn əv ðəm kaɪndli əlaʊd mi tə traɪ aʊt hɪz ɪnstrəmənt (mʌtʃ mɔːr ɪkspensɪv ðəm maɪn).
evriwʌn wəz siːtɪd əraʊnd teɪbl̩z ɪn ə smɔːl rʊm ɪn ðə pʌb (ðə snʌɡ). wʌns ðə seʃn̩ prɒpə wəz ʌndə weɪ, ðə fɔːmən (tʃeəmən) kɔːld ɒn iːtʃ pɑːtɪsɪpənt ɪn tɜːn tə liːd ə tjuːn ɔːr ə sɒŋ. ðə prəʊɡræm wəz ə mɪkstʃər əv ɪnstrəmentl̩ stʌf (fɪdl̩z, kɒnsətiːnə, maʊθ ɔːɡən, mələʊdiənz) ənd ʌnəkʌmpənid sɪŋɪŋ. tuː ruːlz əplaɪd, əz ɪz juːʒuəl ɪn pʌb seʃn̩z — nəʊ æmplɪfɪkeɪʃn̩ ən nəʊ pleɪɪŋ ɔː sɪŋɪŋ frəm ə rɪtn̩ skɔː.
ðə sɪŋəz sæŋ veəriəs fəʊk sɒŋz ən fəʊk-staɪl sɒŋz. wiː ɪnstrəmentl̩ɪss pleɪd ɪŋɡlɪʃ (ənd ʌðə) dɑːns tjuːnz. ðiːz ə tɪpɪkli θɜːti tuː bɑː riːlz, dʒɪɡz, hɔːnpaɪps ɔː wɔːltsɪz, wɪð ðə strʌktʃər AABB. ðə kənvenʃn̩ ɪz ðət ju pleɪ iːtʃ tjuːn θriː taɪmz θruː, ɡɪvɪŋ ʌðə pleɪəz taɪm tə pɪk ʌp ðə melədi ən dʒɔɪn ɪn ɪf ðeɪ kæn.
maɪ əʊn fɜːs kɒntrɪbjuːʃn̩ wəz ə raʊdi riːl kɔːld tʃaɪniːz breɪkdaʊn (Chinese Breakdown), wɪtʃ tə maɪ səpraɪz ði ʌðə pleɪəz dɪdn̩t nəʊ — ɪt wəz wʌn əv ðə steɪpl̩z əv ðə bænd aɪ juːs tə pleɪ ɪn fɔːti jɪəz əɡəʊ — fɒləʊb baɪ ðə krʊkɪd stəʊvpaɪp (Crooked Stovepipe). leɪtə, wem maɪ tɜːn keɪm raʊnd əɡen, aɪ pleɪd dʒesiz hɔːnpaɪp (Jessie’s Hornpipe), seɡweɪɪŋ ɪntə səʊldʒəz dʒɔɪ (Soldier’s Joy), wɪtʃ evriwʌn nəʊz.
In the talk on Multicultural London English that I recently gave in Japan, one of the things I mentioned was a tendency to simplify the phonetics of the indefinite and definite articles by reducing their allomorphic variation. My data came from Kerswill et al., ‘Contact, the feature pool and the speech community: The emergence of Multicultural London English’, Journal of Sociolinguistics 15/2, 2011: 151–196. I am well aware that MLE speakers are not the first NSs to fail to observe the rules that we teach EFL students for the pronunciation of the (that is, ðə before a consonant sound, ði in front of a vowel sound, plus the occasional strong form ðiː). Indeed, I make the point in the note I put in the relevant entry in LPD.
I am well aware that MLE speakers are not the first NSs to fail to observe the rules that we teach EFL students for the pronunciation of the (that is, ðə before a consonant sound, ði in front of a vowel sound, plus the occasional strong form ðiː). Indeed, I make the point in the note I put in the relevant entry in LPD. 
What seems to be true is that ðə plus hard attack before a word beginning with a vowel sound is more frequently heard in MLE than in, say, traditional Cockney or RP. But this is only an impression: I don’t think we have much in the way of hard statistical evidence. The sociolinguists may know its percentage incidence in MLE (see table below), but there’s not a lot of information available about other varieties.  I don’t think I ever say ðə ˈʔæpl̩ and so on myself. But I could be wrong.
I don’t think I ever say ðə ˈʔæpl̩ and so on myself. But I could be wrong.
 At the age of 18, as I was picking up German by staying with a family in northern Germany on a family exchange, I noticed that when wanting to know the time my exchange partner, rather than ask Wie viel Uhr ist es? (‘how many o’clock is it?’), as shown in my tourist’s phrasebook, would usually go for the formula Wie spät ist es? (‘how late is it?’). So I did so too.
At the age of 18, as I was picking up German by staying with a family in northern Germany on a family exchange, I noticed that when wanting to know the time my exchange partner, rather than ask Wie viel Uhr ist es? (‘how many o’clock is it?’), as shown in my tourist’s phrasebook, would usually go for the formula Wie spät ist es? (‘how late is it?’). So I did so too.
Imitating his pronunciation, I pronounced spät as ʃpeːt, using the same vowel sound as in Wie geht’s viː ˈɡeːts ‘how’s it going?’.
As I got to grips with the written as well as the spoken language, I learnt to treat the umlauted letter ä as being pronounced exactly the same as the letter e.
Years later, when I studied phonetics with John Trim at Cambridge, he told me that the German pronunciation I had acquired through total immersion, while commendably native-like in its way, was in some respects regional. If I wanted to speak proper Hochdeutsch, I ought to remember to say Guten Tag! with taːk, not ta(ː)x; the train, der Zug, should be tsuːk, not tsʊx; and for long ä, as in spät, I ought to add a new item to my German vowel system, namely the long ɛː, thus ʃpɛːt.
The standard set out in German dictionaries and textbooks treats orthographic e and ä as having the same value when short, ɛ, but different values when long, namely eː and ɛː respectively.
So fällen ‘to fell’ ˈfɛlən is a perfect rhyme for bellen ‘to bark’ ˈbɛlən (both have the short vowel). But wählen ‘to choose’ should not, in Hochdeutsch, be a perfect rhyme for fehlen ‘to be lacking’ (with the the long vowel): ˈvɛːlən, ˈfeːlən.
This distinction still feels artificial to me, and I don’t make it unless perhaps carefully reading some text aloud or making a phonetic point.
The pronunciation dictionaries tend to hedge their bets on this distinction. Here’s the sixth edition of the Duden Aussprachewörterbuch. Der Vokal [ɛː] kann auch [eː] gesprochen werden… (p. 21: ‘The vowel [ɛː] can also be pronounced [eː]…’)
And here’s the Deutsches Aussprachewörterbuch. Der Unterschied zwischen [eː] und [ɛː] wird in der Aussprache meist nich stark verdeutlicht, so dass häufig ein Vokalklang zwischen [eː] und [ɛː] mit einer Tendenz zu [eː] entsteht. (p. 58: ‘The difference between [eː] and [ɛː] is for the most part not made very clearly in pronunciation, so that frequently a vowel quality between [eː] and [ɛː] arises, with a tendency towards [eː].’)
Wikipedia says, I think quite correctly, The long open-mid front unrounded vowel [ɛː] is merged with the close-mid front unrounded vowel [eː] in many varieties of Standard German…
I shall continue to speak German with an undifferentiated eː.

One or two of the people commenting on nt-reduction (blog, 18 Nov.) also mentioned the possibility of twenty having the vowel ʌ.
Kensuke Nanjo said According to my daily observation of American English, I think this variant is worth including in pronouncing dictionaries. Quite a few Americans use it and as you may know, this is the second variant for "twenty" in the Merriam-Webster Collegiate Dictionary.
 There are indeed plenty (“plunny”?) of Americans who seem to pronounce twenty with a seriously backed and lowered quality as compared with their default DRESS vowel.
There are indeed plenty (“plunny”?) of Americans who seem to pronounce twenty with a seriously backed and lowered quality as compared with their default DRESS vowel.
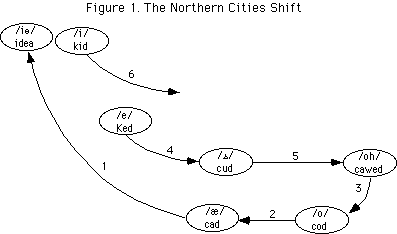
However, in deciding whether this is a sporadic irregularity found just in this word (and perhaps in plenty too), we must first establish what is their default DRESS vowel. We need to discount the possible effects of what, following Labov, has come to be known as the Northern Cities Vowel Shift.
The “northern cities” (of America) in which this sound change flourishes are clustered around the Great Lakes: places such as Buffalo, Cleveland, Detroit, and Chicago. The geographical extent of the shift varies depending on which vowel is involved and in which phonetic environment(s); and in any case it is also socially and stylistically variable. But what it can do is to make DRESS words sound as if they have the STRUT vowel — perhaps all of them, perhaps particularly those in which the vowel is followed by a nasal. Note that the STRUT vowel shifts too, so that we do not normally get loss of the distinctions exemplified in get – gut, bed – bud, wren – run etc.
So someone who says ˈtwɛ̈ni, with a thoroughly retracted vowel, is not necessarily saying ˈtwʌni (“twunny”), to rhyme with funny.
Others, though, are. They include rirelan, who mentioned twenty: /ˈtwʌni/ (along with "plenty" /ˈplʌni/. "plentiful" is still /ˈplɛntəfəl/ though.)
Furthermore, Americans from other, mainly southern or western, parts of the country may merge pen and pin as pɪn (i.e. merge DRESS with KIT before a nasal). For them, twenty may rhyme, if not with funny, then with skinny as well as with many.
Kensuke reckons that a reasonably exhaustive pronunciation dictionary ought to give AmE twenty as ˈtwenti, ˈtwʌnti, ˈtweni, ˈtwʌni. Seems reasonable, though perhaps we ought to add ˈtwɪnti, ˈtwɪni, too.
 The egregious Sepp Blatter, president of FIFA, tried to defuse the impact of his recent inept remarks on tackling racism by getting the newspapers to print a picture of him in the company of Tokyo Sexwale, the black South African politician.
The egregious Sepp Blatter, president of FIFA, tried to defuse the impact of his recent inept remarks on tackling racism by getting the newspapers to print a picture of him in the company of Tokyo Sexwale, the black South African politician.
But how do we pronounce Mr Sexwale’s name? Certainly not ˈseksweɪl.
If you search on-line, you find no authoritative answer and several conflicting pieces of advice from amateurs.
An exchange on reddit went
● Spoiler: Tokyo Sexwale is not pronounced the way it's spelled.
● Yup. As my South African-parented girlfriend immediately pointed out, it's "Seh-tongueclick-wah-leh."
and then● The 'x' in the Sex part is pronounced like a soft 'g' in afrikaans.
Meanwhile the online Telegraph told us firmly Tokyo Sexwale (pronounced seh-wa-le)…
This is one of the names I decided to add to the most recent edition of LPD, so I actually checked it out a few years ago (blog, 3 July 2007).
My initial expectation was that the letter x in his name would stand for the voiceless lateral click, as it does in Xhosa and Zulu, where xoxa ‘tell’ is pronounced ˈǁɔːǁá (or, if you prefer greater explicitness in click symbolism, ˈk͡ǁɔːk͡ǁá).
However, my further researches seemed to suggest that Mr Sexwale’s ethnicity is not Xhosa or Zulu but Venda (or Venḓa — the diacritic indicates a dental, as opposed to alveolar, place of articulation). And in Tshivenḓa the letter x has its IPA value, representing a voiceless velar fricative. So he’d be seˈxwaːle.
The BBC Pronunciation Unit confirmed this. Yes, the IPA for our entry [for Sexwale] indicates a velar fricative. The recommendation is based on the advice of colleagues in Focus on Africa, who, according to our history note from 1993, were adamant that the orthographic 'x' is pronounced as a velar fricative.
(That is indeed also how the orthographic g of Afrikaans is pronounced.)
Conclusion: in English we should call him seˈxwɑːleɪ or, failing that, seˈkwɑːleɪ.
On Friday I said Maybe I’ve just not been keeping my eyes open, but I can’t recall reading any surveys of the prevalence or otherwise of what I would like to call nt-reduction.
 One resource I overlooked has now been brought to my attention by Kensuke Nanjo, phonetics editor of the Genius English-Japanese Dictionary, Fourth Edition (2006), in a long email which is worth quoting in extenso. He claims that this “G4” is
One resource I overlooked has now been brought to my attention by Kensuke Nanjo, phonetics editor of the Genius English-Japanese Dictionary, Fourth Edition (2006), in a long email which is worth quoting in extenso. He claims that this “G4” is
the only dictionary that distinguishes [nd] (t-voicing) and [n] (t-deletion) for underlying /nt/ in American English. G4 gives [nd] for carpenter, certainty, into, ninety, seventy, Washington as their second variant in American English while it shows variants without /t/ for other /nt/-words like center, dental, Internet, plenty, twenty, winter, etc. with the label "casual AmE".
Kensuke says that the decisions he made were
based on some books and papers that I'd read and personal communications with American phoneticians, perhaps including the late Becky Dauer, but I'm afraid I don't very well remember where I obtained the data. This distinction ([nd] vs. [n] for /nt/), however, is mentioned in the phonetics/phonology chapter I wrote for the book Ando & Sawada (eds.) English Linguistics: An Introduction (2001), so I obtained the data more than a decade ago.
He further comments
You rightly mention that "it does not happen in the environment of a following stressed vowel, as in intend, contain", but both LPD and G4 record /nt/-reduction for Antarctic, perhaps as a sole (?) exception.
— probably because of the transparent morphology which makes ant#arctic seem like a compound comparable to print#out, in which nt-reducers do reduce nt.
He continues Also, I agree with your comment that "[it doesn't] apply to ntr clusters, as in country. The t can be lost in centre/center but not in central", but G4 gives the variants like "inner"-duce and "inner"-duction for introduce and introduction respectively, with the label "casual AmE". This is based on my own daily observation about American English. Needless to say, this is a case of r-to-schwa metathesis, which triggers /nt/-reduction. In fact, I tried to include as many cases of common metathesis as possible in G4, so it gives the American casual pronunciation "hunnerd" for hundred, a case of both r-to-schwa metathesis and lexically restricted /nd/-reduction (e.g. can'idate, fun'amen'al, kin'a, un'erstand, won'erful).
These nd-reductions of casual speech are very relevant, too. Thanks, Kensuke.
Maybe I’ve just not been keeping my eyes open, but I can’t recall reading any surveys of the prevalence or otherwise of what I would like to call nt-reduction. By this I mean the loss of t from the cluster nt in intervocalic contexts. This makes winter a possible homophone of winner,
By this I mean the loss of t from the cluster nt in intervocalic contexts. This makes winter a possible homophone of winner,
painting a possible rhyme of straining and dental a potential rhyme of kennel. As far as I know this is not found in any kind of British speech, and we think of it as an American or Australian characteristic.
The possible AmE pronunciation of continental as ˌkɑ̃ːʔn̩ˈẽnl̩ is quite strikingly different from the BrE ˌkɒntɪˈnentl̩.
Several qualifications are needed.
• In the kind of AmE I am referring to, winter may possibly have a nasalized tap, thus ˈwɪɾ̃ɚ, rather than the more deliberate plain nasal of winner ˈwɪnɚ. Trager and Smith (1951) refer to this as a ‘flap-release short nasal’, how accurately I am not sure. In any case, a distinction based solely on ɾ̃ vs. n cannot be very robust. I suspect that in reality for many Americans (and Australians) winter and winner can be, and often are, pronounced identically.
• I have the impression that the incidence of nt-reduction is subject to regional variation in the US. It seems more prevalent in the south and west, less so in the north-east. Is this so? Do Canadians ever do it? It is also probably subject to stylistic variation, with unreduced nt more careful and the reduced variant more casual. Has anyone ever investigated its sociolinguistic characteristics?
• The environments in which nt-reduction operates seem to be the same as those for t-voicing. In particular, it does not happen in the environment of a following stressed vowel, as in intend, contain, nor of a following unstressed but strong vowel as in intake; nor does it apply to ntr clusters, as in country. The t can be lost in centre/center but not in central.
• Some words may be special cases, In particular, I have the impression that ninety in AmE is often ˈnaɪndi rather than the expected ˈnaɪnti or ˈnaɪni. Does the same apply to seventy? Are there other exceptional cases?
• Special cases of a different kind are the handful of words in which a similar reduction is found in BrE, namely in London and some other kinds of popular English. For Brits who do this, the t can be lost from twenty and plenty, and from prevocalic went and want (as in went out, wanted), but not from words such as winter or painting.
This posting was triggered by my hearing an Australian golf commentator on TV referring to ðə ˌsevn̩ˈiːnθ the seventeenth (hole). This violates the constraint barring nt-reduction before a stressed vowel, and I suspect would not be possible in AmE.
Furthermore, I wonder whether Australian English has taken nt-reduction direct from AmE, rather than via some British source? And if so, is it the first instance of such a sound change?
 Latin h tended to be dropped even in classical times, particularly in the middle of words. Thus nihil ‘nothing’ has an alternative form nīl, and mihi an alternative mī, while dē- plus habeo yields dēbeo ‘I owe’.
Latin h tended to be dropped even in classical times, particularly in the middle of words. Thus nihil ‘nothing’ has an alternative form nīl, and mihi an alternative mī, while dē- plus habeo yields dēbeo ‘I owe’.
In initial position it was more tenacious, though even here by classical times it was only the educated classes who pronounced h. At Pompeii, destroyed 79 CE, there are inscriptional forms such as ic for hic ‘this (m.)’, and conversely hire for ire ‘to go’. In his poem about Arrius, Catullus pokes fun at hypercorrections such as hinsidias for insidias. Even the educated sometimes got confused: the letter h in the regular spelling of humor, humerus, and humidus is apparently unetymological.
The Romance languages inherited no phonetic h from Latin. The h that we pronounce nowadays in English words of Romance or Latin origin reflects a spelling pronunciation: habit, hesitate, horror and for most speakers humo(u)r, humid. As we all know, in various other Latin-derived words we have not restored h despite the spelling: there is no h in heir, hono(u)r, honest. In herb Brits and Americans agree to differ.
I was thinking about this because I have been noticing people pronouncing adhere, adherent, adhesion, adhesive without h, thus əˈdɪə etc. In LPD I give only forms that include h — əd ˈhɪə etc. In this I follow Daniel Jones’s EPD, though I notice that the Cambridge EPD now includes the h-less forms. Rightly so; on reflection, I think they are widespread enough to warrant inclusion, at least for BrE.
I have long been aware of the corresponding h-less pronunciation of abhor, which both LPD and the current EPD (but not the DJ EPD) include.
I don’t think there is any tendency towards a spelling-inspired restoration of h in words with the prefix ex-, as exhaust, exhibit, exhilarate, exhort, which all have -gˈz-. But exhale is a notable exception, always having -ksˈh-, and so sometimes is exhume.
You sometimes encounter the hypercorrect spelling exhorbitant for exorbitant. I can’t say I’ve ever heard the corresponding hypercorrect pronunciation, but presumably it exists.
 At the EPSJ conference Takahiro Ioroi presented some statistics about the relative frequency of lexical stress patterns in English words. The pedagogical point was to investigate how far L2 English learners are “exposed to attested patterns in the inputs available”.
At the EPSJ conference Takahiro Ioroi presented some statistics about the relative frequency of lexical stress patterns in English words. The pedagogical point was to investigate how far L2 English learners are “exposed to attested patterns in the inputs available”.
Ioroi did this by combining data on stress placement from the Carnegie Mellon University Pronouncing Dictionary with word frequency data from the British National Corpus and a word list from a collection of EFL textbooks for Japanese schools.
In this way he demonstrated that the most frequent exemplar of an initial-stressed disyllable in the school textbooks was people (at 3606 per million), followed by very, other, many and our (sic), while in the BNC it was other (1336 per million) followed by only, also, people and any.
The methodology was irreproachable. But some of Ioroi’s findings demonstrate the truth of the old adage “garbage in, garbage out”.
Let’s not quibble about our (which NSs usually pronounce as a monosyllable).
What about disyllables with final stress? The most frequent one in the textbook corpus was about, which is fair enough. But the most frequent one in the BNC, and second most frequent in the textbooks, comes out as into.
 Into? But into is stressed on the first syllable, ˈɪntu, ˈɪntə. It does not have final stress. CMUPD says it does: IH0 N T UW1, which is how they represent ɪnˈtuː. CMUPD is wrong, wrong, wrong.
Into? But into is stressed on the first syllable, ˈɪntu, ˈɪntə. It does not have final stress. CMUPD says it does: IH0 N T UW1, which is how they represent ɪnˈtuː. CMUPD is wrong, wrong, wrong.
(In running speech, which is not under consideration here, into may of course lose all stress.)
A useful generalization about English words is that all polysyllables have a primary or secondary lexical stress on either the first or the second syllable. So revolution, for example, has the main stress on the penultimate but on the initial syllable a secondary stress: ˌrevəˈluːʃən. Having supplied stress patterns for several complete dictionary headword lists, I can say that the only exceptions I am aware of are (for some speakers) the two unusual words peradventure and forasmuch. Although they are written as single words, some speakers pronounce them pərədˈventʃə, fərəzˈmʌtʃ, as if they were prepositional phrases, like for a change fərəˈtʃeɪndʒ. (Alternatively, they can be ˌpɜːrədˈventʃə, ˌfɔːrəzˈmʌtʃ, which fit the rule.)
What do Ioroi’s stats tell us about such polysyllables? The most frequent BNC words with lexical stress on neither of the first two syllables are purportedly insufficient and valuation. Again, I am afraid, CMUPD is to blame for supplying wrong information, having forgotten to show secondary stress on the initial syllable of each. (But CMUPD does get the stress pattern of revolution correct.)
For the textbook corpus the results are even odder, since the most frequent such words come out as various proper names, mostly Japanese: Sugihara, Nakamura, Yamagata, Morimoto, Antonelli, which CMUPD shows as having stress only on the penultimate. The fact is that these, too, have initial secondary stress. The incontrovertible evidence for this is the ‘stress shift’ effect when followed by another accented word: ˌSugihara’s ˈwidow (found in this passage).
Again, CMUPD is wrong. GIGO.
 A simple question from a Japanese university student: how is that’d pronounced?
A simple question from a Japanese university student: how is that’d pronounced?
My immediate answer was to tell him that it’s ˈðæt əd. I still think that’s the riɡht short answer, but things are actually a little more complicated.
Some relevant variables:
(i) The that element will have a strong vowel, ðæt, only if it is demonstrative, as in that’d be fun, that’d be OK, I don’t think that’d work. If it is a relative pronoun, as in someone that’d been here before, it will almost always be weak, ðət.
(ii) The ’d element may stand not only for would, as in the examples given, but also possibly for had, as in that’d never worked in the past. This makes no difference to the pronunciation.
(iii) There is also the possibility of pronouncing that’d as a monosyllable, ðæd or maybe ðæt, perhaps with further contextual assimilation: that’d be OK ˈðæbbi əʊˈkeɪ.
(iv) for speakers who use t-voicing (esp. AmE), the intervocalic stop/tap in the disyllabic version will be voiced. Here’s a case in point from YouTube.
I can’t find any dictionary entry for that’d that includes pronunciation. Many dictionaries do not even have entries for that’ll and that’s, but leave their pronunciation to be inferred from entries at that and (if you are lucky) ’ll and ’s. LPD does have entries for these contracted forms, though.

The LPD entry at ’d mentions the comparable it’d but not that’d. But now I wonder if I ought to add the possible monosyllabic versions of both.
More generally, in what varieties and styles is it usual to write contracted that’d rather than the usual full that would, that had? I’m really not sure.
 There were several interesting papers given at the EPSJ conference just over a week ago in Kochi, and I plan to discuss a few of them over the next few days.
There were several interesting papers given at the EPSJ conference just over a week ago in Kochi, and I plan to discuss a few of them over the next few days.
Two of the speakers touched on the use of songs and nursery rhymes in the classroom as pedagogical devices to improve the teaching of pronunciation to EFL students. Both concluded that although they can be valuable they nevertheless need to be handled with caution. This is because the rhythm used in singing is not necessarily identical to the rhythm used by NSs in ordinary speech. (Neither of the two speakers furnished detailed preprints or handouts, so what follows is my own thoughts inspired by their presentations.)
Take the location of stresses. In singing these take the form of the rhythmical beats imposed by the music. Generally speaking, song lyrics reflect lexical stress well: where there’s a lexical stress you get a beat, where there isn’t you don’t. But the correspondence is by no means 100%.
ˈJack and ˈJill went ˈup the ˈhill to ˈfetch a ˈpail of ˈwaˈter
ˈJack fell ˈdown and ˈbroke his ˈcrown and ˈJill came ˈtumbling ˈafˈter.

But in ordinary speech we don’t double-stress water and after. On the other hand we might well stress went and fell.
In particular, rhythmic beats in singing are not a good guide to the deaccentuation of function words. Take this example.
ˈI’m ˈdreaming of a ˈwhite ˈChristmas
ˈJust like the ˈones I used to ˈknow
In these lyrics, since there’s no call for contrastive focus on I’m, in ordinary speech we wouldn’t accent it. (Compare ˈI’m ˈdreaming,| but ˈyou’re aˈwake.) So these lyrics would offer a bad model to those EFL learners who tend to accent pronouns inappropriately.
One speaker got into a terrible muddle with the Burns song Comin’ thro’ the Rye.
Gin a body meet a body
Comin thro’ the rye,
Gin a body kiss a body,
Need a body cry?

For the second body, the music imposes a longer, higher-pitched note on the second syllable than on the first. This led the speaker, if I understood him correctly, to conclude that in the song the word is wrongly stressed, as bɒˈdiː. On the contrary, I would say that it is correctly stressed, and neatly demonstrates the point that in English accent may on occasion be manifested by LOWER pitch than that of a following unstressed syllable, and that in disyllables with a short stressed vowel in the first syllable the second syllable may well be of greater duration than the first.
In any case, the stylized strathspey rhythm of the song is pretty different from the rhythm of ordinary speech. I agree that this song is unsuitable for pedagogical use (except possibly for advanced students), not least because it’s in Scots.
I hope I do not need to add that gin here is pronounced ɡɪn and means ‘if’. Perhaps I ought to add it to LPD.
 The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.
The symbol a is one of the set of symbols representing the ‘Cardinal Vowels’ i e ɛ a ɑ ɔ o u defined by Daniel Jones.